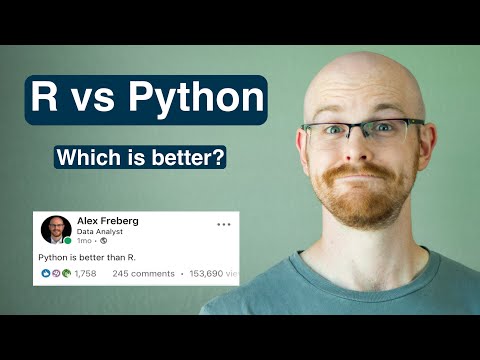
We have a CREATE TABLE IF NOT EXISTS after which the parameter %s the place %s is the placeholder for my desk name. Since we all know the desk schema already in view that we've got the pandas dataframe of our data, we're simply going to call the columns and add the info types. We then save the whole lot in a variable named create_table_command. In this article, I am going to illustrate easy methods to hook up with databases applying a pandas dataframe object. Pandas in Python makes use of a module referred to as SQLAlchemy to hook up with numerous databases and carry out database operations. In the past article on this collection "Learn Pandas in Python", I even have defined easy methods to stand up and operating with the dataframe object in pandas.

Using the dataframe object, you may without problems start off working together with your structured datasets in an analogous means that of relational tables. I would propose you take a seriously look into that article in case you're new to pandas and need to be taught extra concerning the dataframe object. The screen of column metadata is unaffected by the differences within the second script block. You can nonetheless see the column names and their facts types.Python shops string values with an object facts type.

The solely factor not lined in these solutions that I'd prefer to say is that it additionally is dependent upon how you are utilizing SQL. For some rationale not one in each of several arcpy.da capabilities have an execute many feature. This is basically unusual since simply about each different python sql library does. The Where fact within the arcpy.da capabilities is usually constrained to spherical one hundred twenty characters. I must emphasise right right here that pandas is not solely a bit quicker on this case.

It's most quicker that I was actually laughing at myself for not doing it sooner. Using pandas dropped one scripts execution time down from effectively over an hour - I neglect if this was the bounce from 3.5 hours or from 1.5 hours - to actually 12 minutes. The dataframe created from the output of the read_csv carry out receives further processing such asConverting the date column to a datetime index named date. This operation is carried out with the assistance of the inplace parameter for the set_index approach to the df dataframe object.

Setting the inplace parameter to True eliminates the necessity to drop the date column after the conversion. Since Spark 2.2.1 and 2.3.0, the schema is usually inferred at runtime when the info supply tables have the columns that exist in each partition schema and facts schema. The inferred schema doesn't have the partitioned columns. When analyzing the table, Spark respects the partition values of those overlapping columns rather than the values saved within the info supply files. In 2.2.0 and 2.1.x release, the inferred schema is partitioned however the info of the desk is invisible to customers (i.e., the end result set is empty). You could have to put in further driver packages in your chosen database server.
Row['video_id'] and different columns symbolize the columns within the pandas dataframe the place our for loop goes row by row. Df.iterrows() returns two parameters i which is the row index and row which is the row as a tuple, however in our case, we don't should use i, simply row. Let's stroll by using how we will load facts from a pandas dataframe to database desk within the cloud, and carry out a second operation the place we replace the identical desk with new data. We'll do that in a scalable way, which suggests our code can deal with probably tens of millions of rows with out breaking pandas or operating out of memory.

In this article, we'll speak about find out find out how to addContent your facts from a pandas dataframe to a database within the cloud. The first half is to gather facts from an API as your facts source. I took you thru find out find out how to try this in our prior weblog - Working with Python APIs For facts science project. Now that you've the info from the API saved in a pandas dataframe, we have to get it right into a database table. There's a really attention-grabbing task from Dutch CWI, referred to as DuckDB.

It's an open-source embedded analytical database that tries to deal with the SQL mismatch for one among the most common facts science workflow. First quarter-hour of this talk, DuckDB – The SQLite for Analytics, one among many authors, Mark Raasveldt, explains how DuckDB addresses the problem. JSON facts supply is not going to immediately load new information which are created by different purposes (i.e. information that aren't inserted to the dataset as a result of Spark SQL). For a DataFrame representing a JSON dataset, customers have to recreate the DataFrame and the brand new DataFrame will incorporate new files. Notice that the info different varieties of the partitioning columns are immediately inferred. Currently, numeric facts types, date, timestamp and string variety are supported.

Sometimes customers might not wish to routinely infer the info kinds of the partitioning columns. For these use cases, the automated style inference will be configured byspark.sql.sources.partitionColumnTypeInference.enabled, which is default to true. When style inference is disabled, string style might be used for the partitioning columns. Here is a display shot with output from the second main portion of the script. Recall that the second main portion of the script provides a brand new index to the df dataframe founded on the datetime changed date column values from the read_csv edition of the df dataframe. Additionally, the second main portion of the script drops the unique date column from the df dataframe after utilizing it to create a datetime index.

Module can give a wrapper for Google's BigQuery analytics net service to simplify retrieving effects from BigQuery tables employing SQL-like queries. Result units are parsed right into a pandas.DataFramewith a form and facts varieties derived from the supply table. Additionally, DataFrames may be inserted into new BigQuery tables or appended to present tables.
In the above image, you'll word that we're employing the Snowflake connector library of python to determine a connection to Snowflake, very similar to SnowSQL works. We ship our SQL queries to the required databases, tables, and different objects employing the connection object. The consequences set is within the shape of a cursor, which we'll convert right into a Pandas DataFrame.
The first a half of the principle will name the update_db() operate the place we move it the database connection and the pandas dataframe with our video information. That pronounced it does not suggest there aren't area of interest use instances in information evaluation which might be clear up in SQL alone. One instance that I may give is ad-hoc exploratory information visualisation in resources like sqliteviz (in-browser SQLite with full Ploty's array of scientific visualisation) and sqlitebrowser . At this point, we have absolutely replicated the output of our unique SQL question whereas offloading the grouping and aggregation work to pandas.

Again, this instance solely scratches the floor of what's feasible employing pandas grouping functionality. Many group-based operations which are complicated employing SQL are optimized inside the pandas framework. This contains issues like dataset transformations, quantile and bucket analysis, group-wise linear regression, and software of user-defined functions, amongst others. Access to those kind of operations substantially widens the spectrum of questions we're ready to answering. Since Spark 2.3, Spark helps a vectorized ORC reader with a brand new ORC file format for ORC files.
To do that, the next configurations are newly added. For the Hive ORC serde tables (e.g., those created employing the clause USING HIVE OPTIONS (fileFormat 'ORC')), the vectorized reader is used when spark.sql.hive.convertMetastoreOrc can be set to true. The contents of the file are saved in a Pandas dataframe object named df. If you need to put in writing the file by yourself, you might additionally retrieve columns names and dtypes and construct a dictionary to transform pandas facts varieties to sql facts types. Spark SQL can convert an RDD of Row objects to a DataFrame, inferring the datatypes.
Rows are constructed by passing an inventory of key/value pairs as kwargs to the Row class. The keys of this record outline the column names of the table, and the kinds are inferred by sampling the entire dataset, corresponding to the inference that's carried out on JSON files. The pandas-gbq library supplies an easy interface for operating queries and importing pandas dataframes to BigQuery. It is a skinny wrapper across the BigQuery customer library, google-cloud-bigquery.

This matter promises code samples evaluating google-cloud-bigquery and pandas-gbq. First, it illustrates how you can reconstruct the dataframe from the .csv file created within the prior section. The preliminary dataframe is predicated on the appliance of the csv_read perform for the .csv file. Next, three further Python statements monitor the dataframe contents in addition to reveal metadata concerning the dataframe. Examples incorporate knowledge visualization, modeling, clustering, machine learning, and statistical analyses.

Some database structures similar to Apache Hive retailer their knowledge in a location and format which will be immediately accessible to Dask, similar to parquet documents on S3 or HDFS. The constraints imply that we can not immediately settle for SQLAlchemy engines or connection objects, since they've inner state (buffers, etc.) that can't be serialised. A URI string have to be used, which might be recreated right into a recent engine on the workers.
Convert Sql Query To Python Pandas In this tutorial, we'll clarify the best way to import SQL facts and SQL queries right into a Pandas DataFrame. We'll primarily use the SQLAlchemy module to import our SQL data. SQLAlchemy could be utilized along side Pandas for importing SQL facts from quite a lot of varied SQL database types. Once we have now a created a connection to a SQL database, we will use normal SQL queries to entry databases and shop facts into Pandas DataFrames. Python however (pandas is somewhat "pythonic" so it holds true here) is versatile and accessible to persons from varied backgrounds.

It would be utilized as a "scripting language", as a useful language and a totally featured OOP language. When you create a Hive table, you must outline how this desk must read/write knowledge from/to file system, i.e. the "input format" and "output format". You additionally must outline how this desk must deserialize the info to rows, or serialize rows to data, i.e. the "serde". The following selections would be utilized to specify the storage format("serde", "input format", "output format"), e.g.

CREATE TABLE src USING hive OPTIONS(fileFormat 'parquet'). Note that, Hive storage handler isn't supported but when creating table, you possibly can create a desk making use of storage handler at Hive side, and use Spark SQL to examine it. The body could have the default-naming scheme the place the rows begin from zero and get incremented for every row. The columns shall be named after the column names of the MySQL database table. Spark promises a createDataFrame technique to transform pandas to Spark DataFrame, Spark by default infers the schema dependent on the pandas information varieties to PySpark information types.
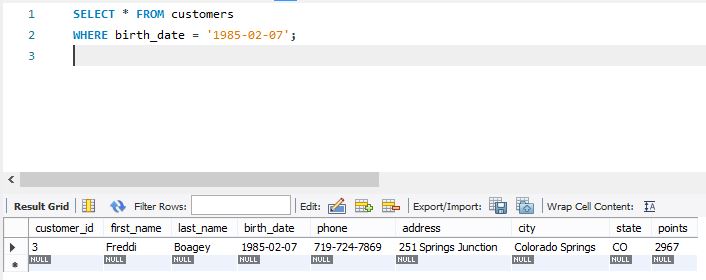
The sqlite3 module grants an easy interface for interacting with SQLite databases. A connection object is created making use of sqlite3.connect(); the connection have to be closed on the top of the session with the .close() command. While the connection is open, any interactions with the database require you to make a cursor object with the .cursor() command. The cursor is then able to carry out all types of operations with .execute(). As you possibly can inform from the previous display shot, the date column within the df dataframe doesn't symbolize datetime values. Therefore, should you wish to carry out tasks, akin to extract date and/or time values from a datetime value, you can't use the built-in Python features and properties for working with datetime values.

However, you'll be able to quite simply use these capabilities and properties after changing the date column values to datetime values and saving the changed values because the index for the dataframe. This part reveals a method to carry out the conversion and signifies its influence on the dataframe metadata. The values zero by using 9 are RangeIndex values for the primary set of ten rows. These RangeIndex values will not be within the .csv file, however they're added by the read_csv carry out to trace the rows in a dataframe.

The full set of dataframe column names and their knowledge varieties seem under the print operate output for the dataframe.The first column identify is date, and the final column identify is ema_200. Set a variable identify with the string of a desk identify you desire to to create. Then use that variable when invoking the to_sqlmethod on the save_df object, which is our pandas DataFrame that may be a subset of the unique knowledge set with 89 rows filtered from the unique 7320. ~ In this case, not solely do you want to append new knowledge as new rows however you might want to additionally replace the values in present rows. For example, since I'm handling Youtube video knowledge from my channel, I even have an inventory of movies on my channel, their view remember and remark count. These counts change over time so once I pull knowledge from the Youtube API a second time, I might want to each replace the counts of present movies and add new movies to the database table.

We'll cross the Postgres connection cursor() referred to as curr and the desk identify to the create_table function. The cursor is a category occasion that lets you run SQL instructions and fetch results. It principally permits python code to execute sql instructions in a database session.

I thought I would add that I do loads of time-series elegant knowledge analysis, and the pandas resample and reindex techniques are invaluable for doing this. Yes, you are ready to do associated issues in SQL (I are likely to create a DateDimension desk for serving to with date-related queries), however I simply discover the pandas techniques a lot less difficult to use. In this benchmark we copy a Pandas knowledge body consisting of 10M 4-Byte integers from Python to the PostgreSQL, SQLite and DuckDB databases.

This needless to say will solely work if the database server is operating on the identical machine as Python. Using DuckDB, you can still reap the benefits of the robust and expressive SQL language with out having to fret about transferring your information in - and out - of Pandas. DuckDB is very straight forward to install, and presents many advantages akin to a question optimizer, automated multi-threading and larger-than-memory computation. Like ProtocolBuffer, Avro, and Thrift, Parquet additionally helps schema evolution.

Users can start off with an easy schema, and progressively add extra columns to the schema as needed. In this way, customers could find yourself with a number of Parquet information with totally different however mutually suitable schemas. The Parquet knowledge supply is now capable of immediately detect this case and merge schemas of all these files. DataFrames could even be saved as persistent tables into Hive metastore employing the saveAsTablecommand. Notice that an present Hive deployment shouldn't be essential to make use of this feature.
Spark will create a default neighborhood Hive metastore for you. Unlike the createOrReplaceTempView command,saveAsTable will materialize the contents of the DataFrame and create a pointer to the info within the Hive metastore. Persistent tables will nonetheless exist even after your Spark program has restarted, so lengthy as you preserve your connection to the identical metastore. A DataFrame for a persistent desk will be created by calling the desk way on a SparkSession with the identify of the table. You additionally can manually specify the info supply that will be used together with any further selections that you'd wish to cross to the info source.

Data sources are specified by their absolutely certified identify (i.e., org.apache.spark.sql.parquet), however for built-in sources you too can use their brief names . DataFrames loaded from any information supply kind might be changed into different sorts applying this syntax. Now, the info is saved in a dataframe which may be utilized to do all of the operations. In order to put in writing information to a desk within the PostgreSQL database, we have to make use of the "to_sql()" approach to the dataframe class. This system will examine information from the dataframe and create a brand new desk and insert all of the information in it. A URI referred to above is an easy connection string that may be utilized by the module to ascertain a reference to the PostgreSQL database.
In the primary part, you might want to say the database taste that you're connecting to. It could very well be "mysql" or "mssql" counting on the database that you just just just use. In the second a half of the connection string, you might want to specify the username and password that you'll be making use of to hook up with the database server. Note that the username and the password are separated through the use of colons. In the third part, you might want to say the database hostname and the port on which the database is running, observed by the database name.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.